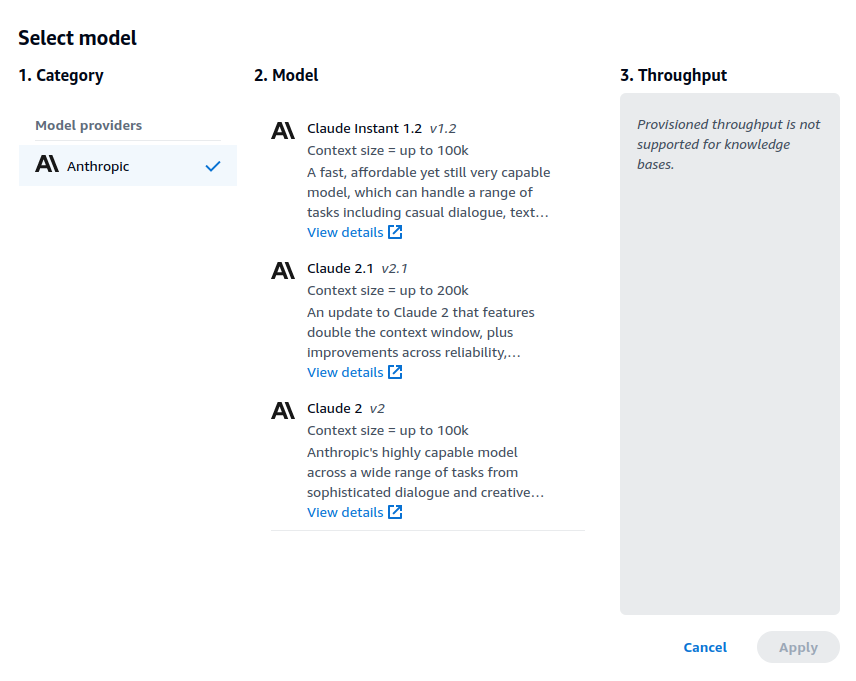
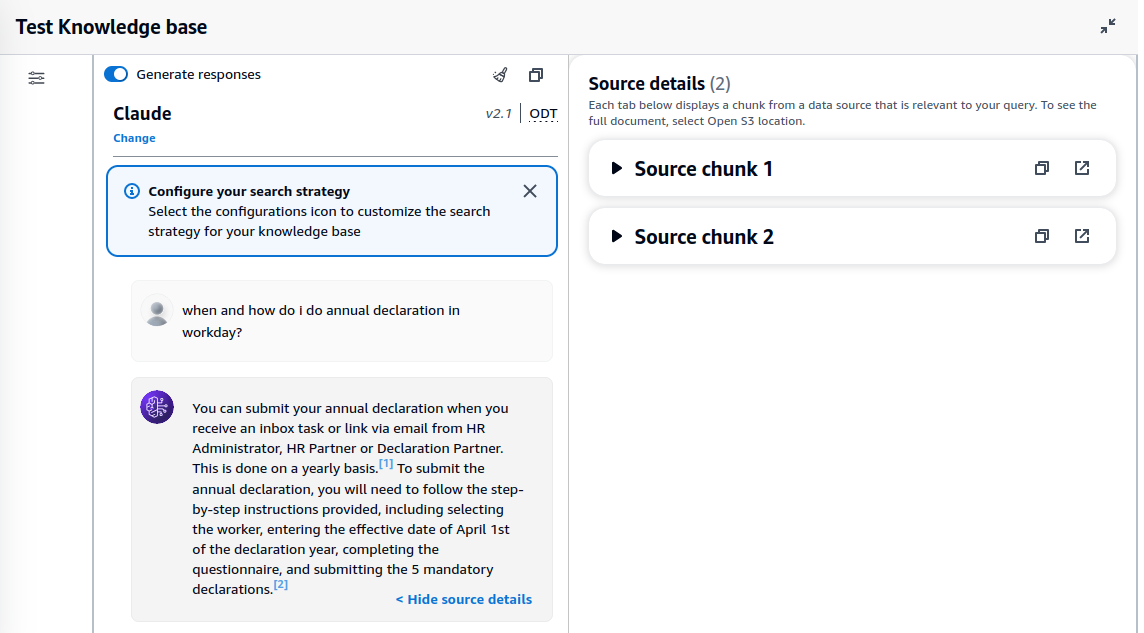
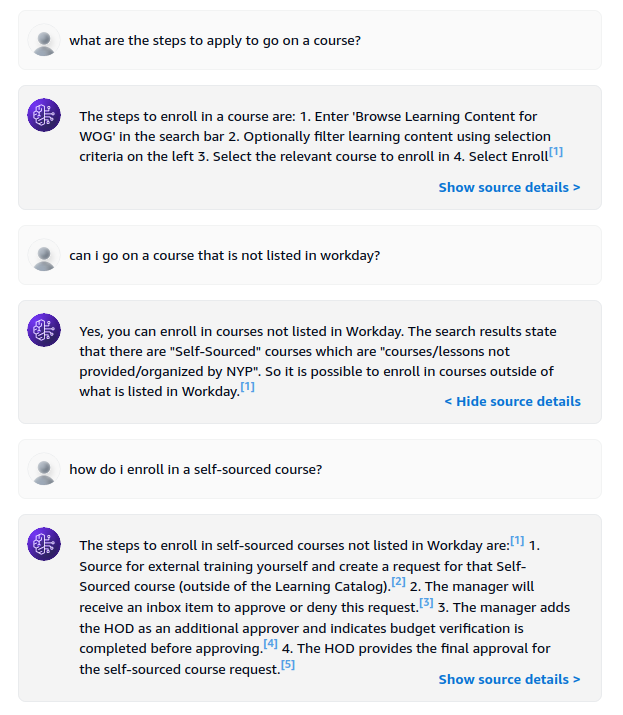
In Part 1, I showed how you can set up an Amazon Bedrock Knowledge Base (ABKB for short) using the AWS console. I also showed how you can perform queries against the knowledge base via the playground in AWS console. In this article, I will show how you can do the same thing via AWS CLI.
First, make sure you are using the latest version of the CLI. Otherwise some commands might not be available. To see if your CLI supports the commands, run
aws bedrock-agent-runtime help
It should return something like this:
BEDROCK-AGENT-RUNTIME() BEDROCK-AGENT-RUNTIME()
NAME
bedrock-agent-runtime -
DESCRIPTION
Amazon Bedrock Agent
AVAILABLE COMMANDS
o help
o retrieve
o retrieve-and-generate
Next, make sure you have the access and secret keys configured in AWS CLI. You can do it via the usual aws configure but I usually do it in a profile since I have many AWS accounts/IAM users, eg. aws configure --profile demo. For convenience, I will use alias to use the new profile like this: alias aws='aws --profile=demo --region=us-east-1'
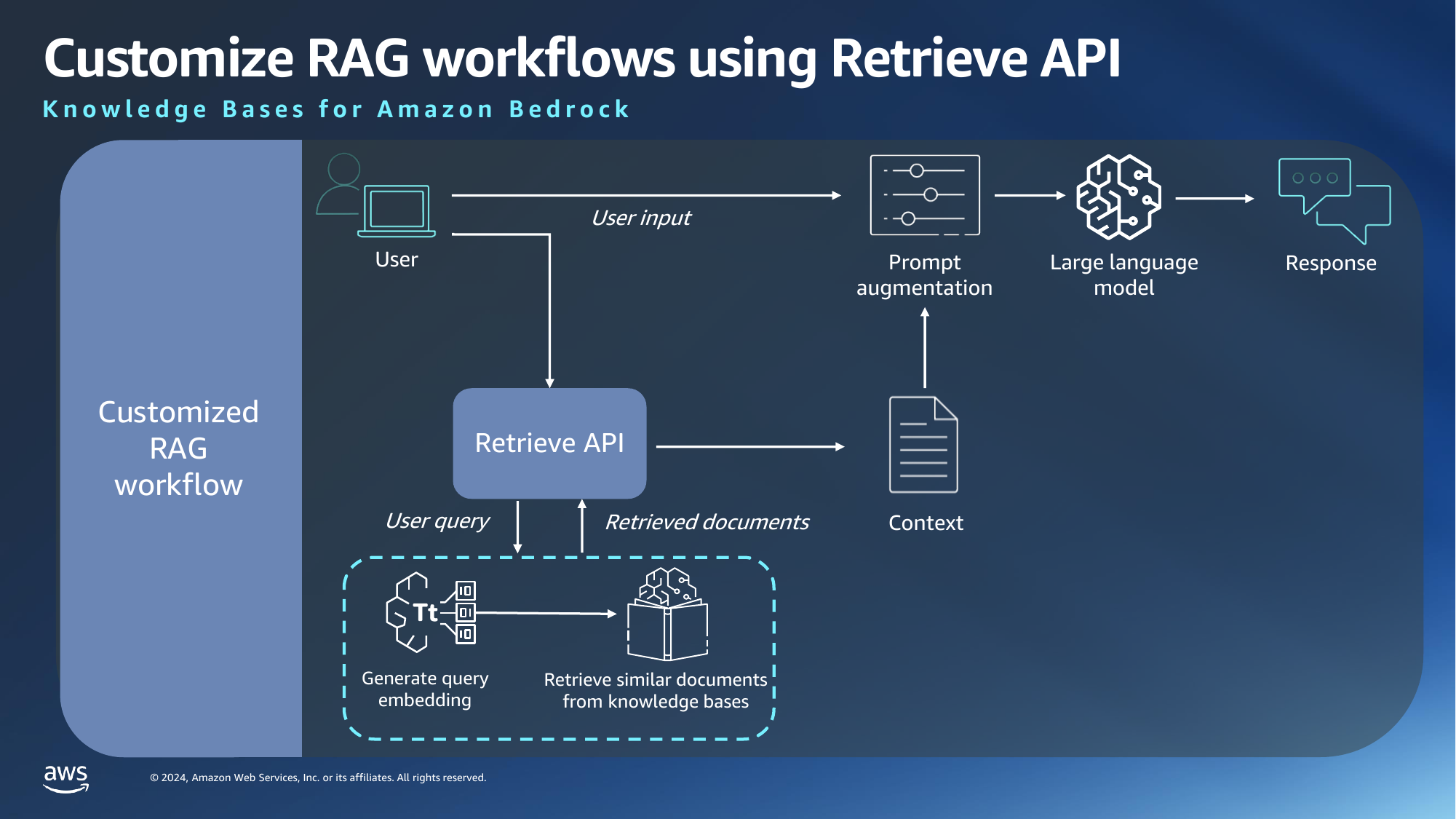
We can now test the retrieve command in CLI. To run the command, you will need the knowledge base ID. Strangely, there is no way to get this via the CLI 🤷.For now just copy the value from AWS console. Once that is done, you are ready to run the CLI command. Omitting optional/default parameters, this is an example of the simplest version of the command:
aws bedrock-agent-runtime retrieve \
--knowledge-base-id LEBQPJQ9BY \
--retrieval-query '{ "text": "how to apply for leave" }'
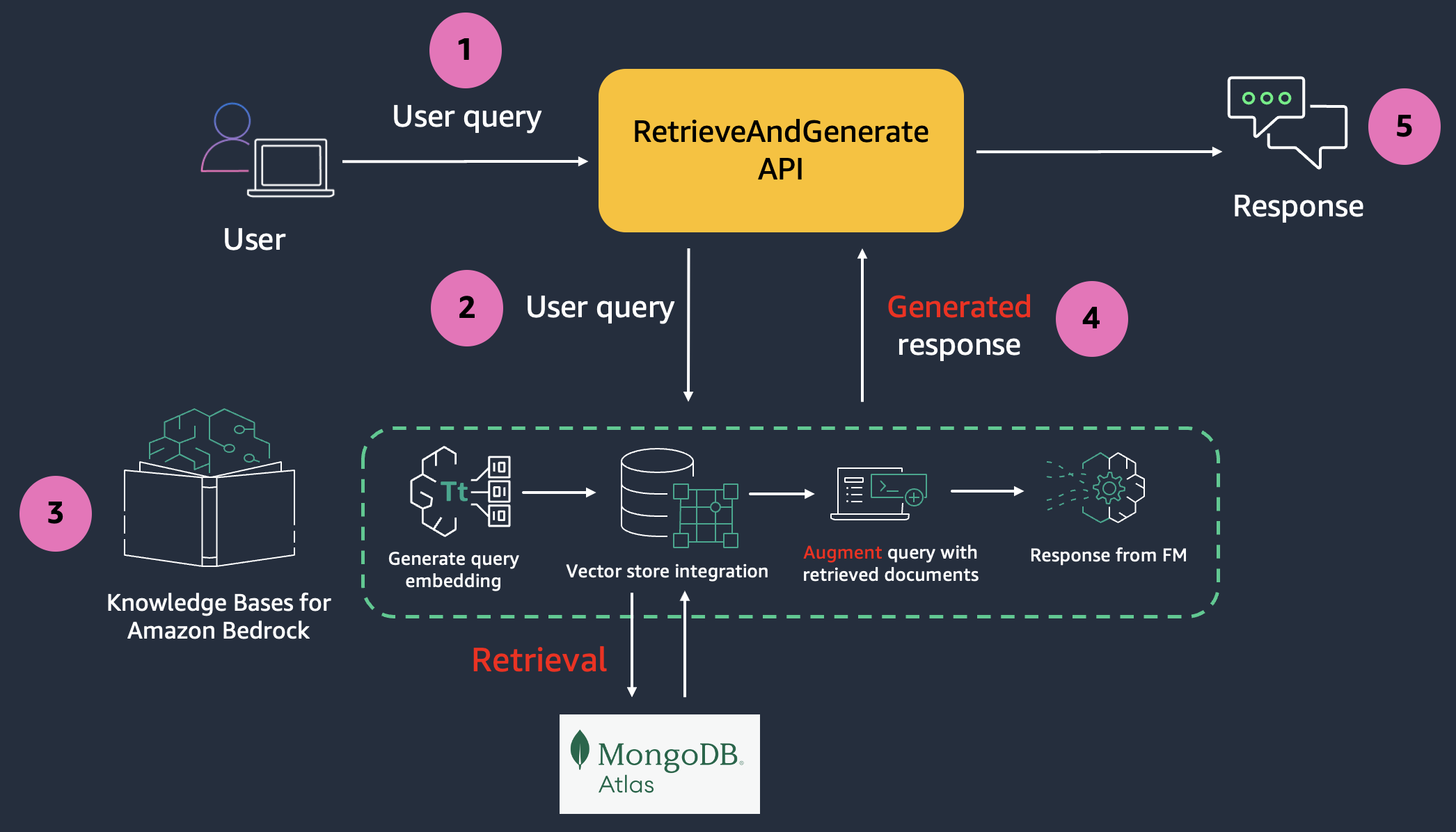
Retrieve performs a vector search using the query text and returns a list of matches with a score. As mentioned in Part 1, if you are implementing a custom RAG workflow, you can use the output of retrieve as the context for further prompting. Score ranges from 0-1, 1 being most relevant.
{
"retrievalResults": [
{
"content": {
"text": "<trimmed>"
},
"location": {
"type": "S3",
"s3Location": {
"uri": "s3://<trimmed>"
}
},
"score": 0.75545114
},
{
"content": {
"text": "<trimmed>"
},
"location": {
"type": "S3",
"s3Location": {
"uri": "s3://<trimmed>"
}
},
"score": 0.7345349
},
(Note: output trimmed for brevity and sanitization)
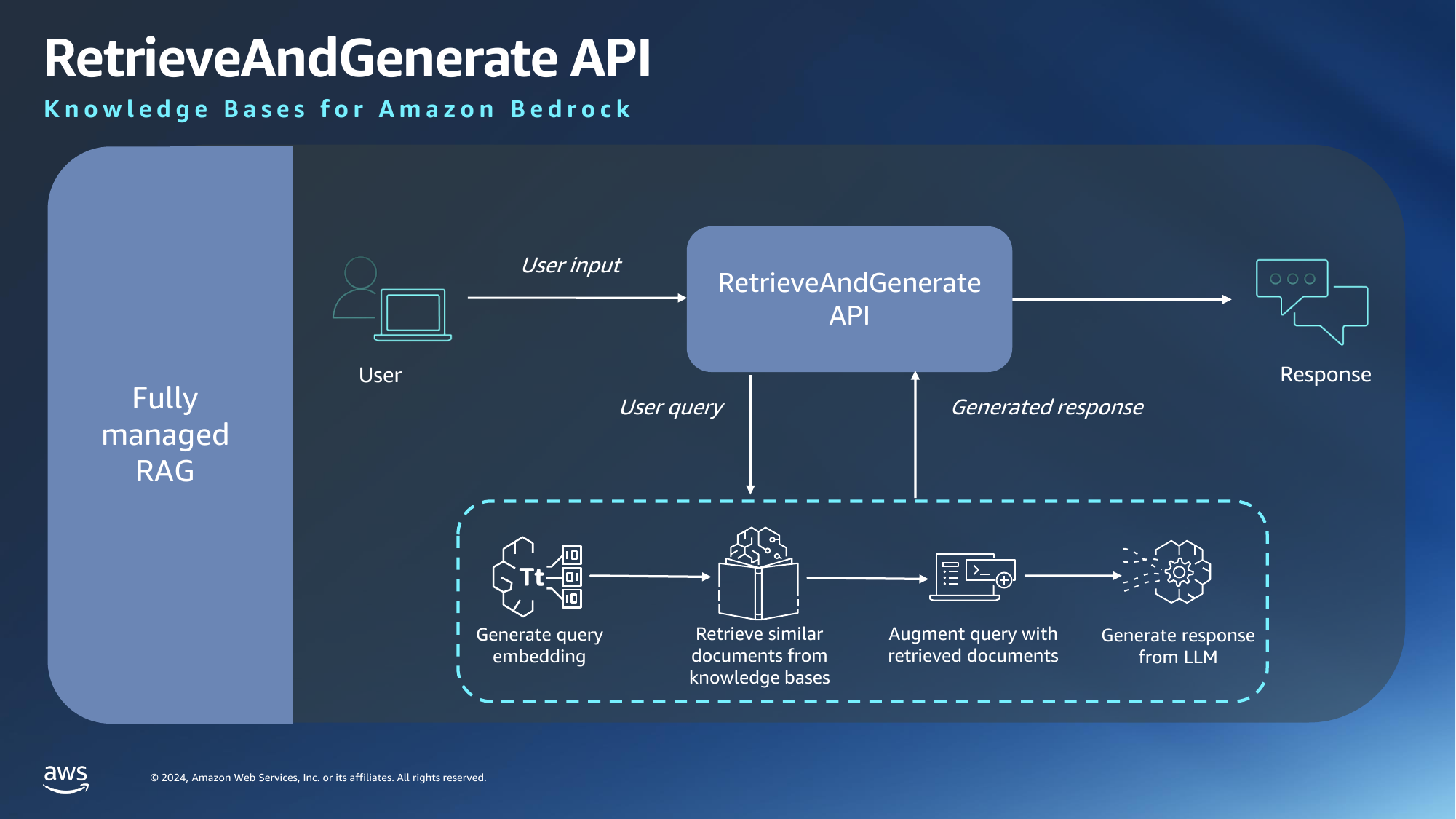
Next we will test retrieve-and-generate command, which implements the fully managed RAG workflow.
Unlike some other CLI commands which uses model id, you will need the model ARN for querying. There is currently no way to get the model ARN from AWS console, so you will need to get it via another CLI command:
aws bedrock list-foundation-models
Not all models can be used in ABKB – at least for now. Stick to Claude Instant V1, V2, V2.1 and only use ON_DEMAND models. I made the mistake of choosing a PROVISIONED model and all I get is a cryptic error message. Yikes.
An error occurred (ValidationException) when calling the RetrieveAndGenerate operation: 1 validation error detected: Value 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-instant-v1:2:100k' at 'retrieveAndGenerateConfiguration.knowledgeBaseConfiguration.modelArn' failed to satisfy constraint: Member must satisfy regular expression pattern: (arn:aws(-[^:]+)?:bedrock:[a-z0-9-]{1,20}:(([0-9]{12}:custom-model/[a-z0-9-]{1,63}[.]{1}[a-z0-9-]{1,63}/[a-z0-9]{12})|(:foundation-model/[a-z0-9-]{1,63}[.]{1}[a-z0-9-]{1,63}([.:]?[a-z0-9-]{1,63}))|([0-9]{12}:provisioned-model/[a-z0-9]{12})))|([a-z0-9-]{1,63}[.]{1}[a-z0-9-]{1,63}([.:]?[a-z0-9-]{1,63}))|(([0-9a-zA-Z][_-]?)+)
With the right model ARN in hand, you are ready to execute the retrieve-and-generate command. Here is an example of the command you can execute:
aws bedrock-agent-runtime retrieve-and-generate \
--input '{ "text": "how to apply for leave" }' \
--retrieve-and-generate-configuration '
{
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "LEBQPJQ9BY",
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-instant-v1",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"overrideSearchType": "HYBRID"
}
}
},
"type": "KNOWLEDGE_BASE"
}
'
If all goes well, you will get an output like this:
{
"sessionId": "0ff48086-f26f-4ebd-bb68-7c7bcd1e414a",
"output": {
"text": "To apply for leave, navigate to the Workday homepage and select the Absence worklet. Then select \"Request Absence\" and choose the date range and type of leave you want to apply for. You may need to provide additional details or attachments depending on the leave type. Finally, select \"Submit\" to complete the request."
},
"citations": [
{
"generatedResponsePart": {
"textResponsePart": {
"text": "<trimmed>",
"span": {
"start": 0,
"end": 317
}
}
},
"retrievedReferences": [
{
"content": {
"text": "<trimmed>"
},
"location": {
"type": "S3",
"s3Location": {
"uri": "s3://<trimmed>"
}
}
},
In an earlier attempt, I included numberOfResults in vectorSearchConfiguration and got an error message. Note that numberOfResults is currently unsupported.
Closing Thoughts
While writing this article, I noted some general observations in the terms of CLI/console usage:
- Use of model id vs model ARN: some CLI commands use model id while others use model ARN
- Some information can only be found in AWS console (eg. knowledge base id), others only via AWS CLI (eg. model ARN)
- Inconsistent naming in CLI (eg. –retrieve-query vs –input) and error message (error message refers to numResults while actual field is numberOfResults)
Since ABKB is so new there are bound to be some rough edges here and there. None of these are showstoppers and I expect them to clear up over time as the service becomes more mature. For now do be aware as the service undergoes rapid development and updates.