Amazon Bedrock is a fully managed service designed to simplify the development of generative AI applications – as opposed to Amazon SageMaker which provides services for machine learning applications. It offers access to a growing collection of foundation models from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon itself.
One of the latest offering under Amazon Bedrock is Amazon Bedrock Knowledge Base – which I shall refer to as ABKB. Essentially, ABKB is a simple way to do retrieval augmented generation (RAG). RAG is a technique to overcome some of the problems with foundation models (FM), such as not having up-to-date information and lack of knowledge of organization’s own data. Instead of retraining or fine tuning a FM with your own data, RAG allows existing FM to reference those data when responding to a query to improve accuracy and minimize hallucinations. In this article, I will go through the process of setting up ABKB and see how it can be used it in a sample application. But first, let’s look at the 2 ways you can use ABKB in a RAG application:
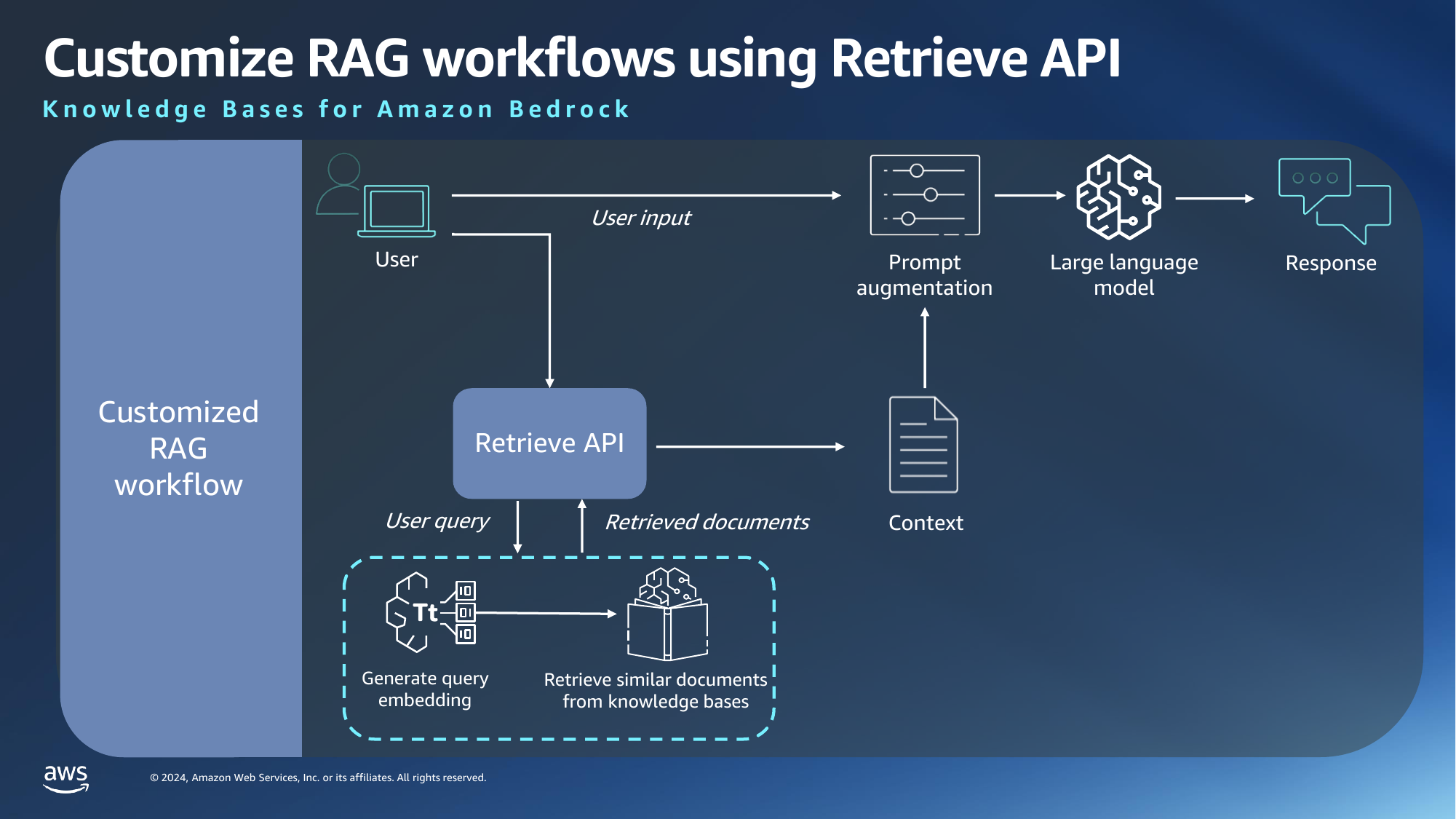
Custom RAG workflow is useful for cases where you want to have more control over the prompt augmentation process, or where you want to use FM which are not available in AWS. Here, you are only using AWS to generate embeddings – which is a technique to convert words into a numerical form – and to retrieve similar documents from user prompts.
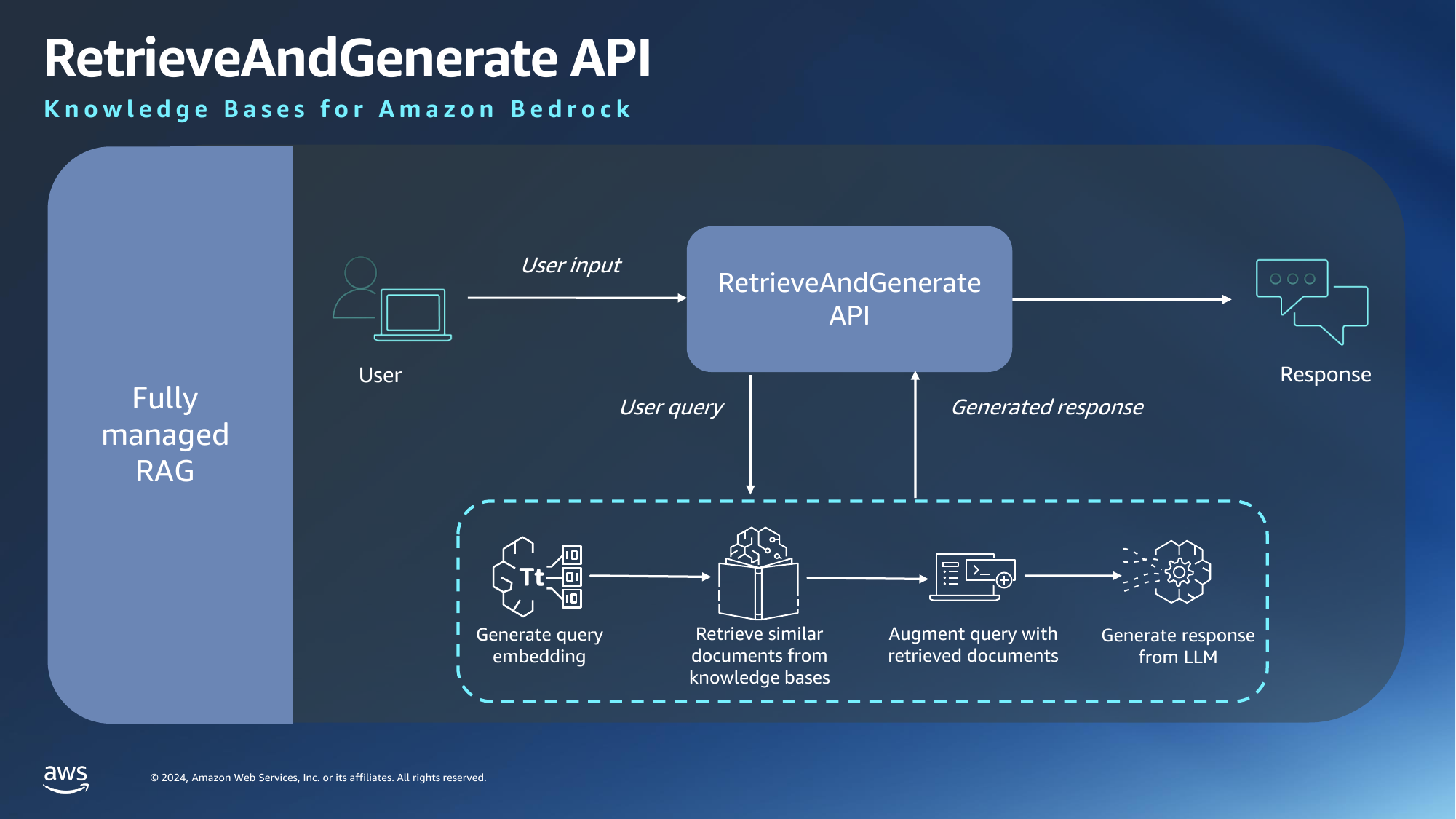
In a fully managed RAG workflow, we will use AWS for all stages of the pipeline and this is what we will be doing.
Things to take note
As it is with new services, Amazon Bedrock is currently available only in limited regions. We will be using the US East (N. Virginia) region.
Note that you will need to login as an IAM user, not root user, to use ABKB. Suffice to say the IAM user will need to have sufficient permissions.
Request model access
Before you can use any Bedrock services, you will need to request for permission to the models that you want to use. This is done under the Model access option on the left panel.
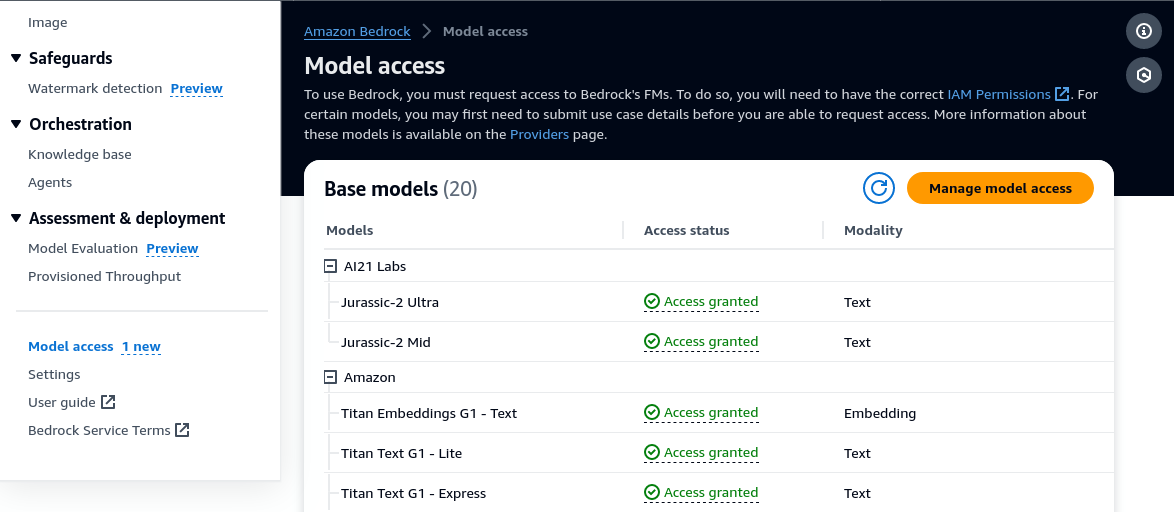
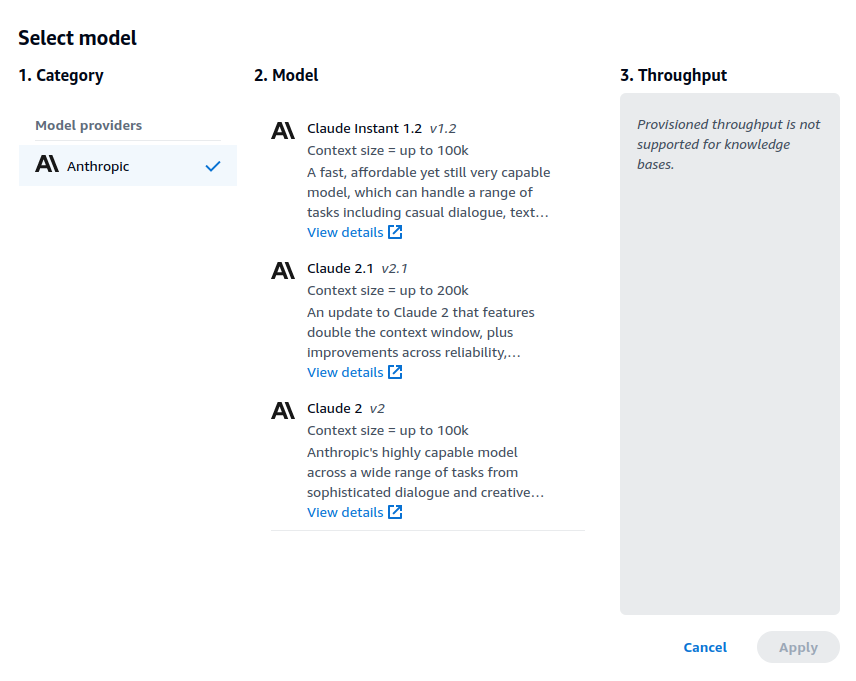
There is no cost to request for model access so you might as well request for everything. The main reason for this step is to make sure you agree to the EULA for each model which will be different for different providers. Access to most models are automatically granted after request, except for Anthropic models, which you will need to provide a use case. You will need to do this because ABKB only supports Anthropic models at this point for its retrieve and generate API.
Create data source
ABKB takes data from a S3 bucket as its data source, so you will need to use or create a S3 bucket. Use the same region as the knowledge base if you are creating a new bucket.
There are some limitations to the size and type of documents supported. Mainly, documents should not exceed 50MB in size and it will only process text in supported documents (txt, md, html, doc, csv, xls, pdf).
Create knowledge base
There are 4 steps to create a knowledge base. Step 1 is straightforward and just involves filling in the name, description and IAM permissions – which you can leave as default.
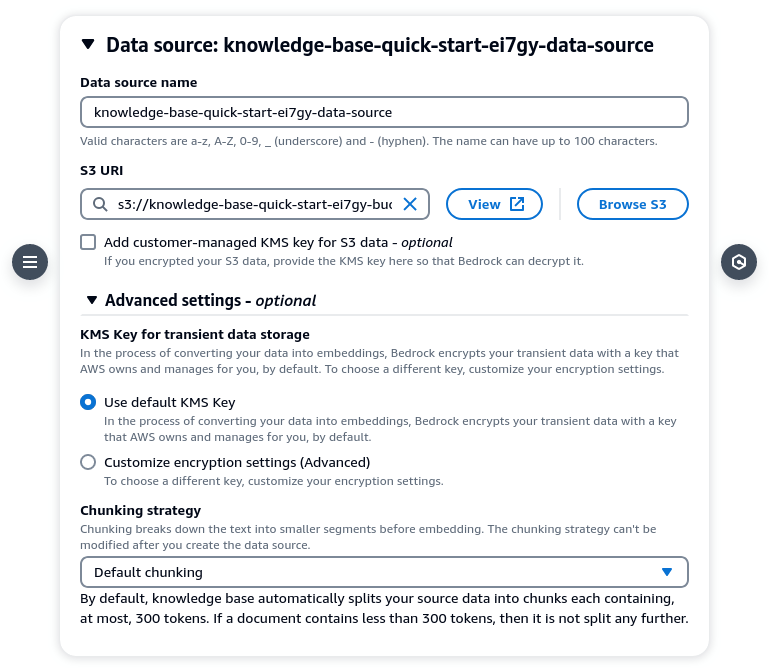
In Step 2, you will need to specify the data source. By right you should be able to click on [Browse S3] and choose your bucket but it was not working for me. So enter the S3 URI manually if you need to. For chunking strategy you can leave it as default (300 tokens) or customize it according to your needs.
In Step 3, choose your embeddings model and vector database. You can choose between Amazon Titan or Cohere’s model for embedding. There are some articles that says Cohere’s models are superior. You can choose either and evaluate the performance. For vector database you can select Amazon OpenSearch Serverless, Aurora, Pinecone or Redis Enterprise Cloud. For development and testing, OpenSearch Serverless provides the cheapest option.
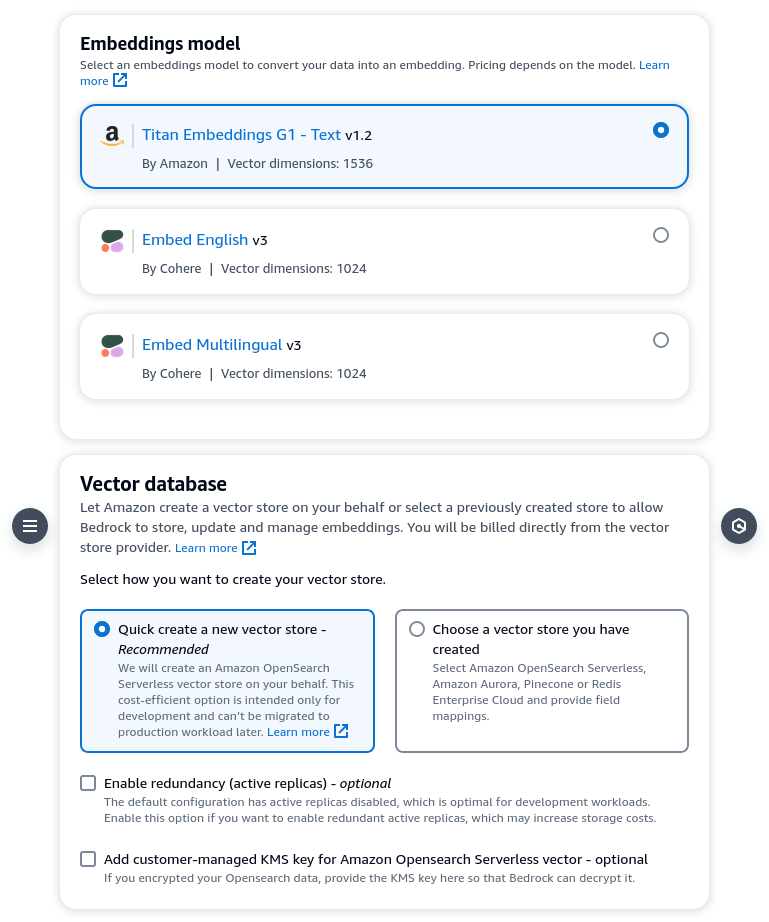
Step 4 is basically just a confirmation step. Click [Create knowledge base] to confirm. Note that it will take some time to provision the necessary resources after you click. While that is happening, do not close your browser tab. This is quite unusual as provisioning usually takes place in the background and there should not be a need to keep the frontend open, but that is not the case here.
Assuming all goes well, you will see a message to say that the knowledge base has been created successfully. You might have to wait a few more minutes for the vector database to fully index contents from the data source.
Test knowledge base
Now comes the fun part. you can now select your knowledge base and test it in the playground. You can configure the search strategy and model under configuration. Depending on your use case you might want to change the search strategy.
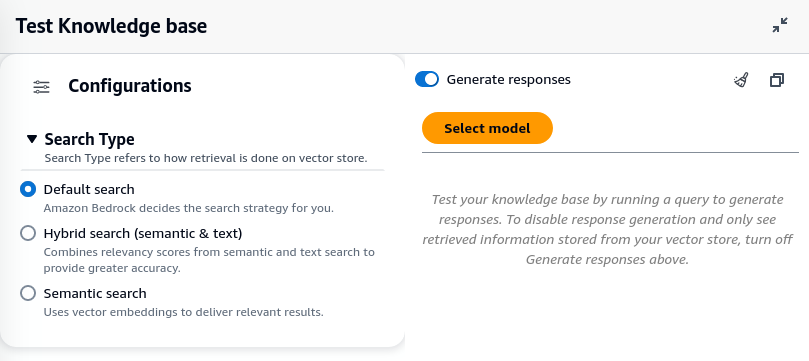
For model selection, Claude Instant provides the fastest response, but it does not perform as well for complex queries. I find almost no difference in Claude 2 and 2.1, but that is probably because my queries do not require a larger context window.
Sample responses
To test ABKB, I uploaded a 238 page employee user guide and use it to ask questions. The first one is a simple question.
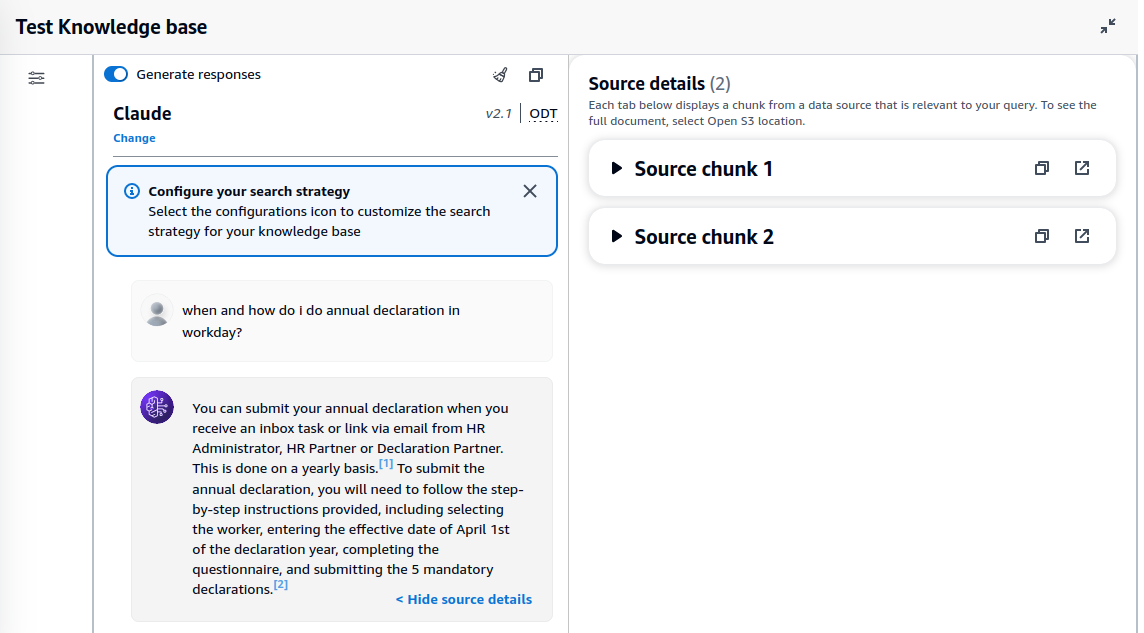
Note that the response includes references to source chunks, which are relevant text that are extracted from the data source. You can also expand source chunk to see the actual text.
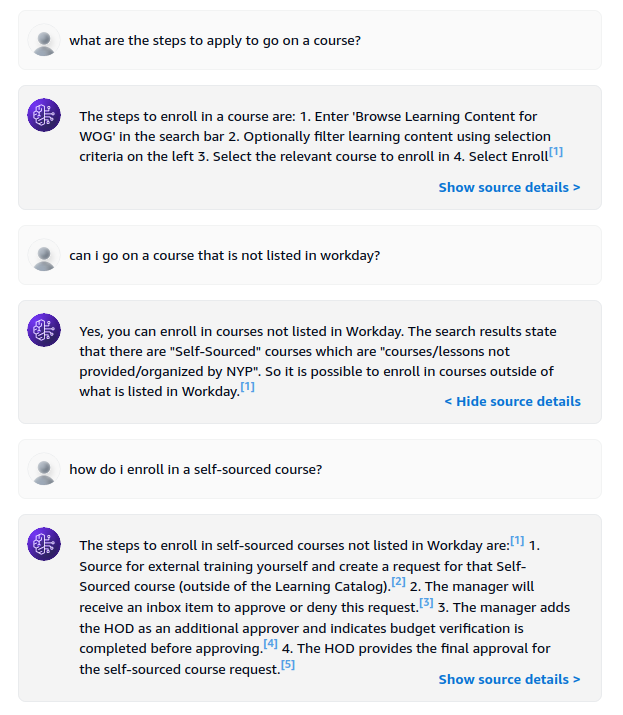
The second example is one where I asked follow-up questions.
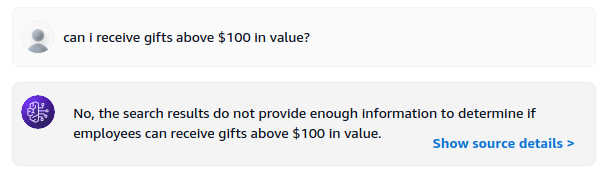
I also tried to ask it something which is not in the document. To which it responded correctly that there is no such information.
Conclusion
Amazon Bedrock Knowledge Base provides an opinionated way to do RAG in a straightforward manner. The knowledge base you create is meant to be integrated into applications via AWS SDK. As it is fairly new at this stage, some rough edges are to be expected. Some of the issues encountered so far includes:
- Model request UI not straightforward
- Browse S3 not listing buckets unless they are already a data source
- Provisioning requires staying on the page
- Only Anthropic models available for response generation
New models like Anthropic Claude 3 not availableAnthropic Claude 3 models are now available- Failure to create knowledge base happens sometimes
Despite the teething issues, ABKB seems like a useful service for organizations to create RAG applications easily within the AWS ecosystem and I am excited to see the addition of more features to enhance its functionality in the upcoming weeks/months.