It is always good to have diversity in benchmarks, to avoid over-reliance and overfitting on one set of benchmarks. AWS just released SWE-PolyBench, their benchmark to evaluate AI coding agents’ ability to navigate and understand complex codebases.
Unlike SWE-Bench, which only works for Python code, SWE-PolyBench is designed to work for additional languages like Java, JavaScript and TypeScript.
Today, Amazon introduces SWE-PolyBench, the first industry benchmark to evaluate AI coding agents’ ability to navigate and understand complex codebases, introducing rich metrics to advance AI performance in real-world scenarios. SWE-PolyBench contains over 2,000 curated issues in four languages. In addition, it contains a stratified subset of 500 issues (SWE-PolyBench500) for the purpose of rapid experimentation. SWE-PolyBench evaluates the performance of AI coding agents through a comprehensive set of metrics: pass rates across different programming languages and task complexity levels, along with precision and recall measurements for code/file context identification. These evaluation metrics can help the community address challenges in understanding how well AI coding agents can navigate through and comprehend complex codebases
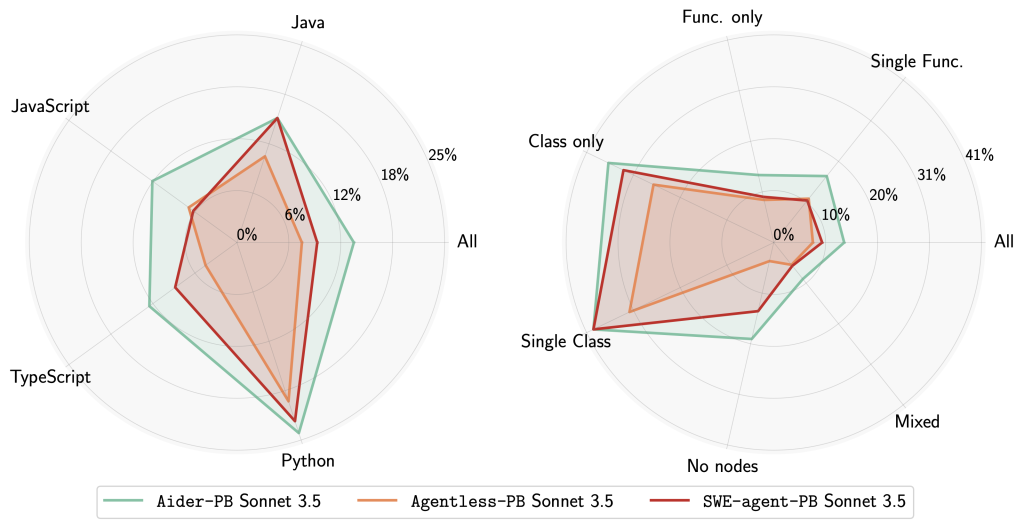
Perhaps unsurprisingly, Amazon Q Developer Agent is currently leading this benchmark in the leaderboard. It remains to be seen how well-adopted this new benchmark will be.