I was helping a friend to troubleshoot their e-commerce site. It was running on WordPress using WooCommerce as the e-commerce backend. Like most WordPress sites, it was installed with a ton of plugins. My friend complained that the site performance has been getting slower and slower, to the point where a page load can take anywhere from 2-3 seconds to a failing to load at all. Getting to wp-admin also took forever.
At first, there are a lot of pieces to unravel, since the cause might be anything. The backend was running on AWS. The WordPress site is running as a docker container on the EC2, while the database is running on a RDS instance. It uses Cloudflare tunnel to connect the public hostname to the docker container. Seems like a decent setup.
While I do use WordPress (this site runs on WordPress), I am not a WordPress developer so I was not familiar with where things might go wrong. My first intuition was to check the plugins, since not all WordPress plugins are well written and some are notorious for taking up a lot of resources. Unfortunately isolating plugin resource usage by instrumentation was not possible as far as I know, due to the way WordPress/PHP works. After comparing the set of plugins with another site which did not exhibit the same behaviour, I decided to try other approaches.
I tried the usual tricks, like enabling proxying in Cloudflare, using a caching plugin, upping the EC2 instance size and RDS instance size. I even added a robot.txt to prevent bots from crawling the site for the time being. Those tricks helped a little, but did not resolve the problem.
Using docker stats, I noticed that CPU and memory usage is extremely high for the container, compared to others. CPU consumption is often >100% with every page load and memory usage spiked to 14GB after a while. Another unusual sign is the size of the database. For a site with around 500 products, the database size is >600MB.
That is when I chanced upon this article when searching for the symptoms.
The problem WordPress sites can run into is when there is a large amount of autoloaded data in the wp_options table.
…
If you return anything below 1 MB you shouldn’t be worried. However, if the result was much larger, continue on with this tutorial.
I ran the query in the article and it returned the following.
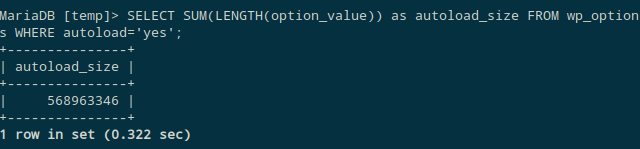
Wait. The autoload_size is ~570MB (!). I wrote a SQL command to find all the options which are larger than 1MB.
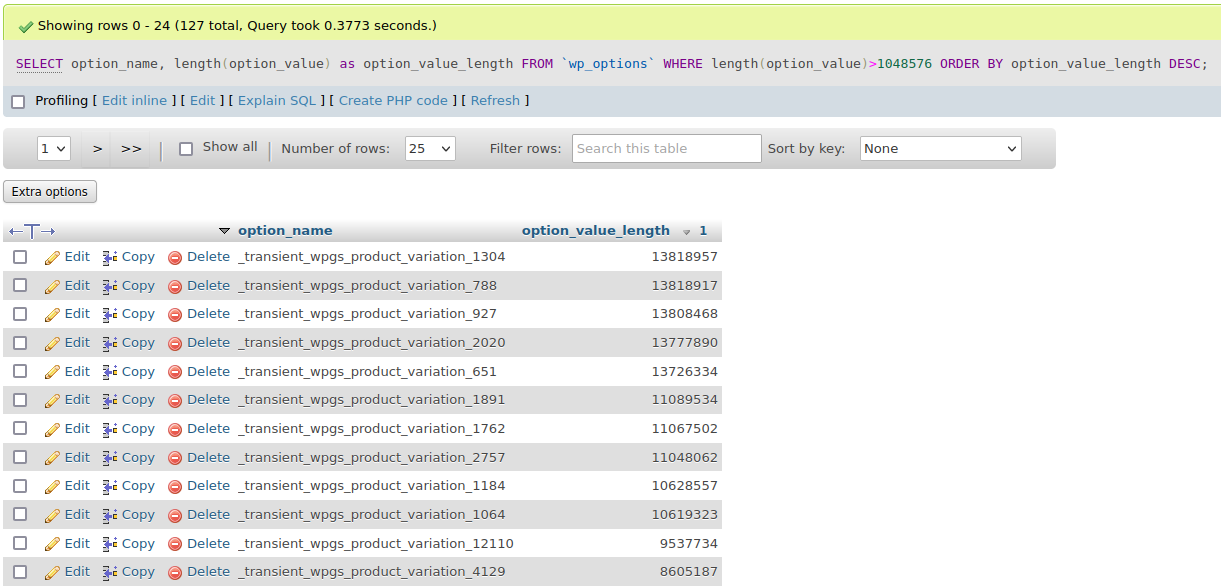
The results range from 1MB all the way to 13MB.
For the uninitiated, wp_options is akin to Windows registry, and it has become a dumping ground for plugins to store values that they might need. Most of the values in this option should be configuration values (like siteurl) which should take up just a few bytes. wp_option also has a field “autoload” which states whether the option should be loaded on every page. Storing 13MB in an option value and setting it to autoload is just insane. The total size of autoload options in the table turns out to be >500MB. Every page load is querying >500MB of data from the database and processing those data. No wonder the site is crawling!
Inspecting those options shows them most of them have the prefix _transient, which means they can be safely deleted. After making a backup of the database, I deleted all transient options. wp_options went from 556MB to 46MB, a reduction of >90%. The total database size went from 645MB to 84MB, a reduction of >85%. Memory consumption also dropped by 20x (from ~14GB to ~700MB). More importantly, the site is now super fast which is extremely important for an e-commerce site.
The results are very telling from the RDS dashboard.
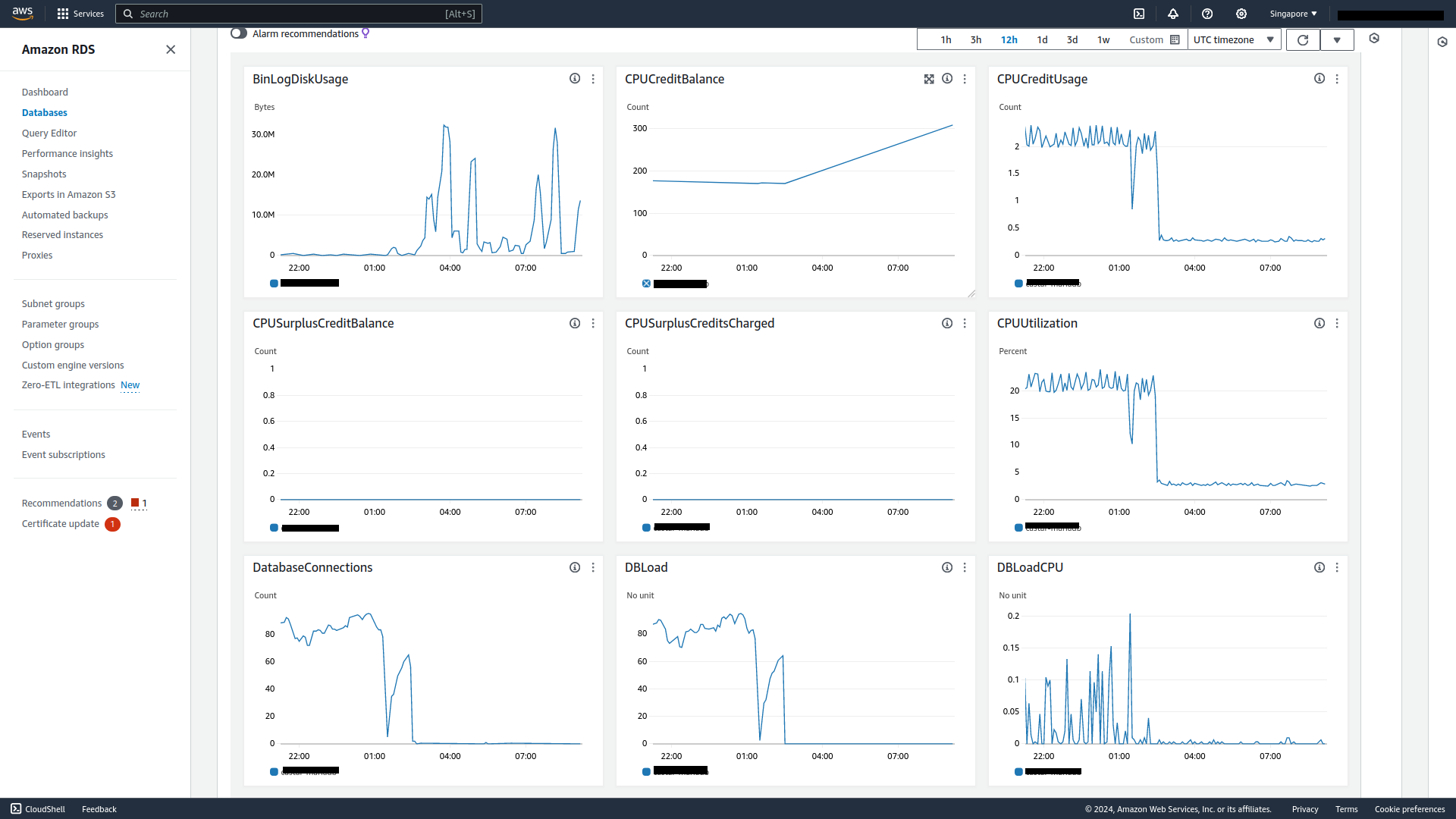
Average CPU utilization has dropped to <3% and average database connections is now near zero.
Aside from noticeable performance boost for the site – average page loads within 1s – another bonus from these optimizations is that we can now use smaller EC2 and RDS instance types for better cost savings. Hopefully this article is useful as a reference for others in similar situations.